- HOME
- FE EXAM
- PE EXAM
- DESIGN TOOLS
- COURSES
- STORE
- ABOUT
- CONSULTING
![]()
Engineering Pro Guides is your guide to passing the Mechanical & Electrical PE and FE Exams
Engineering Pro Guides provides mechanical and electrical PE and FE exam technical study guides, practice exams and much more. Contact Justin for more information.
Email: contact@engproguides.com
ELECTRICAL FE EXAM TOOLS
Probability & Statistics for the
Electrical FE Exam
by Justin Kauwale, P.E.
Introduction
Probability and Statistics accounts for approximately 4 to 6 questions on the Electrical FE exam. Statistics is primarily used in the electrical and computer engineering fields for data analysis and prediction, reliability, i.e. failure rates, and statistical quality control. This section focuses on the following NCEES Outline topics, Measures of Central Tendencies and Dispersions, Probability Distributions, Expected Value and Estimation for a Single Mean.
Probability Distribution involves applying a mathematical formula to describe the probability of a measured or recorded variable occurring at a certain value. This is useful for characterizing the measured output of any electrical or computer system property when you are taking a sample of a larger number. For example, when you measure 100 points, this is only a sample of an infinite amount of points that could have been recorded. A probability distribution will help to characterize the data with the limited 100 measurements that were made.
Expected Value uses weighted averages of each value to produce the most likely value.

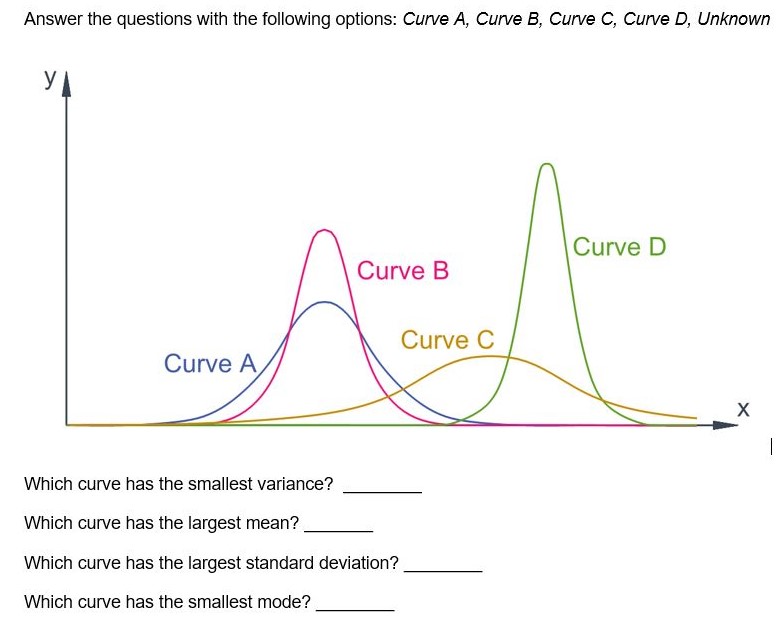
2.0 MEASURES OF CENTRAL TENDENCIES AND DISPERSIONS
Before you get to probability distributions, you need to understand some of the basic topics in probability like the difference between samples and population, mean, mode, standard deviation. As you go through these topics, you should remember that probability is used in mechanical engineering to measure the reliability of a set of data points.
The mean of a set of data points is calculated by summing up all the values and dividing by the total number of data points. The mean is also known as the average.

Sometimes this term can also be called arithmetic mean. An example calculation for finding the mean is shown below for the sample data set.
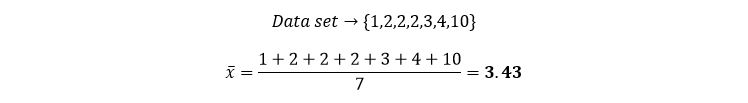
The mode is the measured value that appears the most in a set of data points. In the sample data set from the previous topic, the mode will be “2”.
The median is the measured value that occurs in the middle of the data set. The median is found by first ordering all the data points in ascending or descending order, then finding the middle value. If there is no middle value (i.e. there are an even number of data points), then you must take the average between the two middle values.
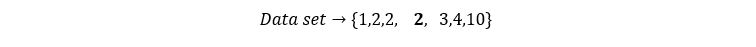
The median in the previous example is “2”.
The geometric mean is used to give equal weight to a set of data points with high volatility. The geometric mean is found by multiplying the data points and taking the nth root of the product, where n is equal to the number of data points.
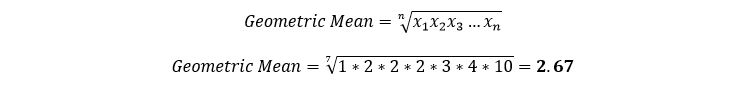
On the FE exam, just be careful to read the problem correctly and to make sure you calculate the correct mean. If the question does not specifically state geometric mean, then you can assume that arithmetic mean is required.
The standard deviation is used to characterize the amount of variation between a set of values. A set of values with a large variation, may lead you to not trust the average of those values or the set of values. A set of values with a small variation, will more likely lead you to trust the average of those values and the set of values itself. Large variations imply volatility, while small variations imply consistency and reliability.
Standard deviation is calculated by first finding the mean, then calculating the difference for each value from the mean. Next, square these differences and sum up the square of the differences. Finally divide by the number of data points, then take the square root of the sum. The equation is shown below.
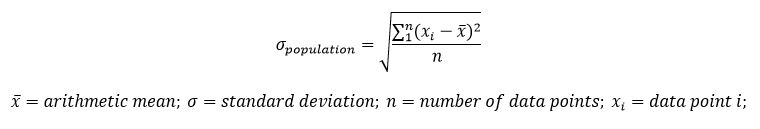
It is important to note that you can only use this equation when you have a complete set of data points. In the NCEES FE Reference Handbook, this equation is called the standard deviation for a population. This just means that you have the complete set of data points and you are not taking a sample of the complete set of data points. If you are taking a sample of data points, then you must use this formula to calculate the standard deviation.

3.0 PROBABILITY DISTRIBUTIONS
The NCEES FE Reference Handbook has a set of probability distribution tables. These tables take the probability formulas and put the results into tables. There are several probability distribution formulas, (1) Binomial, (2) Normal, (3) t-Distribution and (4) x2 Distribution. These tables generally describe the probability of obtaining “x” successes, within “n” attempts or samples, with an individual probability of success equal to “P”. This is often used to predict and test the probability of success, given a number of samples.
BINOMIAL DISTRIBUTIONS
A binomial distribution is used when there are only 2 outcomes. Typically in engineering, these two outcomes are described as yes or no, success or failure, pass or do not pass, and defective or satisfactory. The following table shows the cumulative binomial probability of success, given “n” independent trials or experiments, “x” successes and “p” individual probability. Say for example you are to flip a coin. The amount of times you flip a coin is “n”, the number of trials. These trials are independent because one does not affect the other. Let’s assume that heads is a success and tails is a failure. The number of heads flipped throughout the trials is “x” the number of successes. Finally, the likelihood of each flip being a heads is 50%, so “p” the individual probability is 0.5. For a set number of trials, n, the binomial distribution will graph out the probabilities of x successes from 0 to n trials. The cumulative binominal probability table includes all probabilities of success from 0 to x. The main objective is to understand how to read and use the Cumulative Binomial Distribution table.
Table 1: This table is read by first identifying the correct column to look at. The columns corresponds to the probability of success for each individual trial or sample. For example, you can assume the individual probability of success is 0.1, meaning that the probability that each product will come out successful is 10%. Next, determine the combination that you want. A combination is the number of successes “x” out of a total number of trials “n”. For example, if you want to know the probability of 0 successes out of 2 trials, then you would find the probability as 0.81. This means that there is an 81% chance that you will select two samples or run two trials and both will be failures, meaning you have zero successes. This table is shown as cumulative, so if you navigate to right below that point you will see a value of 0.99. This means that there is a 99% probability that out of two trials you will either have 0 successes or 1 success. If you calculate the difference between x=1 and x=0, then you will have the probability that there is exactly 1 success, which is 0.99-0.81=0.18 or 18%.
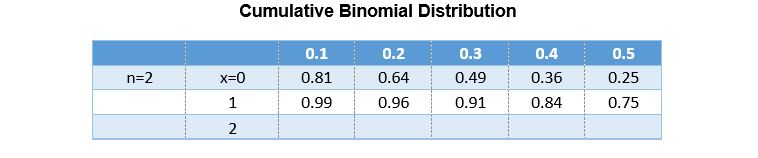
It is very important that you understand the probability of success is cumulative in these tables as you move from x= 0 down to x = 1.
A normal distribution is shown as the figure below. In order to answer these problems, you have to use a different method from the binomial distribution table. The outline of the normal distribution curve may look similar to the binomial distribution at times, but its values are different.
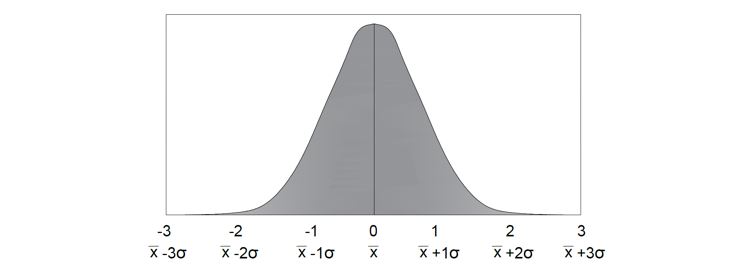
Figure 1: This figure shows the normal or Gaussian distribution. This can also be shown in table form. It shows the probability of a sample’s value appearing a certain standard deviation away from the mean. There is a high probability of the value appearing at the mean, then 1 standard deviation away, then less probability at 2 deviations away and finally least probability at 3 standard deviations away.
This graph can be used as follows. The first way is through the R(x) values. These values tell you the probability that the sample will occur in the range to the right of the (x) value. The (x) value is the number of standard deviations away from the arithmetic mean. This tells you the probability that the sample will occur in the range right of the (x) value of standard deviations away from the arithmetic mean.
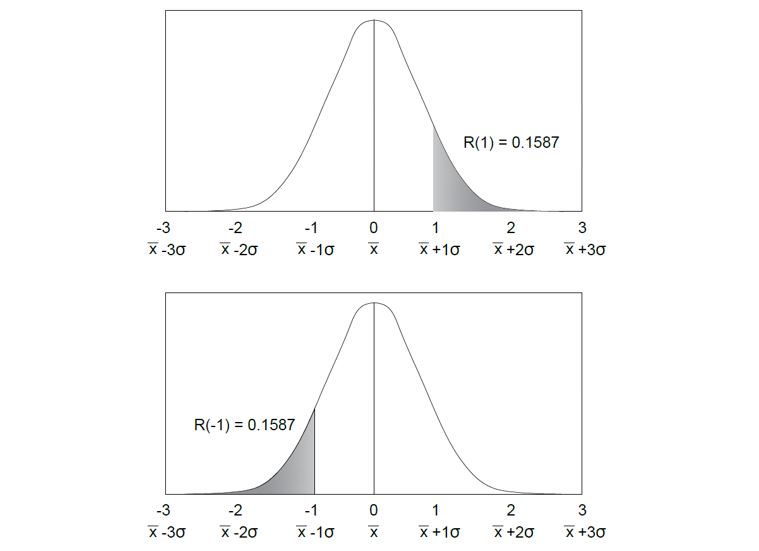
Figure 2: The first way you can look at the normal distribution tables is through the F(x) value. This value is normally used as shown in the top figure. But you can also use it in its inverse format. You can find out the probability that the sample will occur to the left of the negative standard deviations away from the arithmetic mean.
The next way you can use the normal distribution curve is through the F(x) values. These values tell you the probability that leads up to the (x) value when you move from left to right. As you can see this is the inverse of the R(x) values.
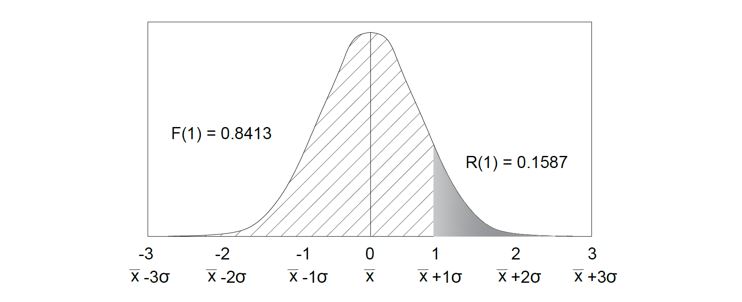
Figure 3: The second way you can look at the normal distribution tables is through the F(x) values. This is the inverse of the R(x) values, meaning that R(x) +F(x) = 1.0.
The third and fourth ways of analyzing the normal distribution is through the W(x) and 2R(x) values. The 2R(x) values is simply found by multiplying the R(x) values by 2. This value tells you the probability that the sample will occur at a value greater than the absolute value of (x) deviations away from the mean. The W(x) values show you the inverse of the 2R(x) values. This describes the probability that a sample will occur at a value less than or equal to the absolute value of (x) deviations within the mean.
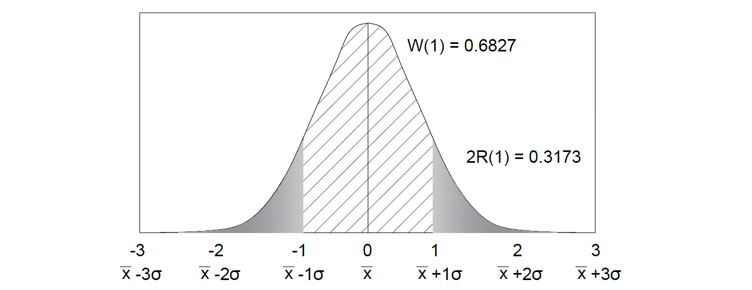
Figure 4: The third and fourth way you can look at the normal distribution tables is through the 2R(x) and W(x) values. The W(x) is the inverse of the 2R(x) values, meaning that 2R(x) +W(x) = 1.0.
T-DISTRIBUTIONS
Please see the technical study guide for this discussion.
X2-DISTRIBUTION
Please see the technical study guide for this discussion.
4.0 EXPECTED VALUE
The expected value takes into account the probability of all the possible outcomes. It multiplies the probability of each outcome by that outcome and then adds up all of these terms. For example, let’s say that the probability of a test is either 75, 85 or 95 and the probability of a 75 is 20%, the probability of 85 is 50% and the probability of 95 is 30%, then the expected value can be calculated as shown below.
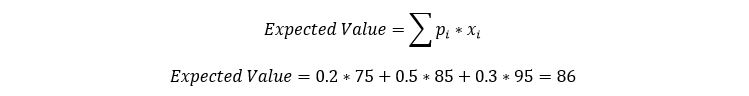
This imparts a weighted average on each of the values, giving higher influence to the value that is expected to occur more often.
5.0 ESTIMATION FOR A SINGLE MEAN
The NCEES FE Electrical and Computer outline also makes reference to a subtopic called Estimation for a Single Mean with the other sub-sub topics (point, confidence intervals, conditional probability). This all makes reference to the T-distribution under probability distributions. The T-distribution helps you to determine confidence in the population mean.
6.0 Practice Problems
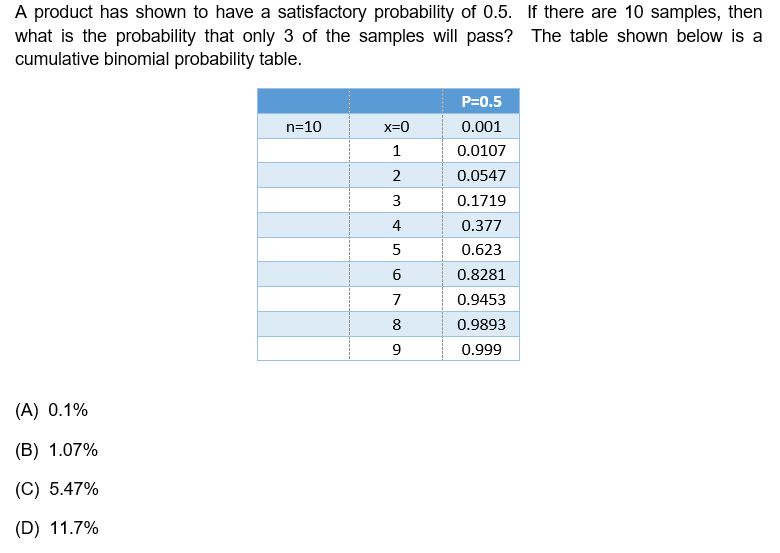
PRACTICE PROBLEM 1 – BINOMIAL DISTRIBUTION
10.2 PRACTICE PROBLEM 2 – STANDARD DEVIATION

10.3 PRACTICE PROBLEM 3 - PROBABILITY DISTRIBUTION